Datasets
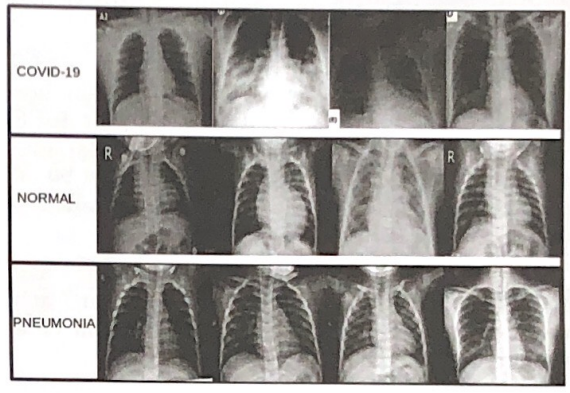
COVID-19(2021)
We collect images and annotate them with medical imaging specialists. In particular, COVID-19 include 1,517 NORMAL cases, 1,467 PNEUMONIA cases, 439 cases. In addition, images are gathered from sources: COVID-19 Radiography Database, Covid-19 Image Dataset, COVID-19 PatientsLungs X Ray Images 10000, COVID-19 High quality images.
UIT-DODV(2021)
UIT-DODV is the first Vietnamese document image dataset, including 2,394 images with four classes: Table, Figure, Caption, Formula. UIT-DODV converted 1,696 images from PDF with size 1,654 x 2,338, 247 images scanned from the physical scanner and expanded with 451 images scanned from the smartphone.
UIT-DODV has the following highlights:
- Variety of images: images in our dataset are of two types, with images converted from PDF as complete documents and images. Scan images often have lower resolutions depending on the scanning angle as well as the lighting conditions that can cause the document page to be blurred, distorted, skewed, or obscured.
- Variety of layout: data collected from other scientific conferences/journals, a common feature of these conferences/journals is that they often use their templates (typically document pages can represent document pages in the form of one column or two columns).
- The challenge comes from data classes: with the simultaneous use of two formula objects (Formula) and Caption creates a challenge for our dataset as well. As in building detection models for these objects. The vast majority of a document page is represented as text, so spotting these objects quickly is very difficult.

UIT-VEMC21(2021)
Vietnam’s ethnic minority costumes gradually receive more attention through images which performed by KOLs or in music videos. The need of searching national costumes is increasing day by day. However, it is quite difficult to collect data on images of ethnic minority costumes on the internet. Therefore, we built a dataset about Vietnamese Ethnic Minority Costumes Classification (UIT-VEMC21), consisting of these 10 most largest ethnic groups: Tay, Thai, Muong, H’Mong, Dao, Ede, Ba Na, Cham, San Diu, Ra Glai.
Our dataset consists of 10 categories: Tay, Thai, Muong, H'Mong, Dao, Ede, Ba Na, Cham, San Diu, Ra Glai, which are carefully checked and labeled by certain sources. Samples are collected from 10 volunteers who wearing and changing 2-3 outfits. These photos were taken in clear and cloudy weather during the day.

UIT-VinaFruit20(2021)
UIT-VinaFruit20 contains 63,541 images are corresponding to 20 Vietnam popular fruits, with the average images per class are about 3,700 images. UIT-VinaFruit20 is the first Vietnamese fruit dataset with four main features promising more challenges.
UIT-VinaFruit20 has the following highlights:
- Diversity in the color of one fruit. We collected both images from unripe fruit to the fruit we can eat, which has a different color in each period of fruit. Furthermore, the similarity in color between fruit is also an element concerned.
- Similar in shape. Fruit categories from our dataset cover various high intra-class distances (different look but similar type) and low inter-class distances (similar look but another type).
- Diversity in the appearance of fruit in the image. We didn't limit the images to only contain one fruit in them. Therefore, the fruit can appear in various locations of an image with many sub-objects. For example, fruit can occur in a meal that includes others food, or fruit is set up into a basket gift contains another item.

UIT-CVID21(2021)
With the current situation of traffic in Vietnam, we are facing many outstanding problems, especially traffic congestion since the supply of infrastructures has often not been able to keep up with mobility growth. A large number of CCTV, radar sensors are installed to monitor vehicles and collect traffic information, which helps agencies to keep track of traffic flow, vehicle density and parking status. However, these methods do not provide a sufficient overview to develop and solve the current situations.
Recently, images taken from UAVs have been easy to collect and extremely useful due to their ability of covering large areas in a single image and high resolution in a small number of locations. Thanks to this high resolution, vehicles can be detected even small objects such as cars and motors. But, to be able to solve the problem of vehicle detection well, we have to have a good classification model which can deal with the current situation of traffic in Vietnam. So that, our team built a dataset named UIT-CVID21 (Classifying Vehicle In Image From Drone) which can reflect the reality of Vietnam traffic to create premises for later studies and address problems such as traffic density management, traffic separation and traffic congestion.
UIT-CVID21 has 10,000 images which include four classes: bus, car, truck and van. This is one of the first dataset in this present time that has captured the most diverse angles and clearly show the characteristics of Vietnamese road thanks to the flexibility of unmanned aerial equipment (Drone).

UIT-Drone21(2021)
Thanks to the advantage of high mobility, Unmanned Aerial Vehicles (UAVs) are used to provide many essential tasks in computer vision, bringing more efficiency and convenience than fixed surveillance cameras or ground moving sensors with limited angle and visibility. UAVs have many practical applications. However, drone datasets are still limited, and they focus only on a few specific tasks, such as visual tracking or object detection in certain situations.
In this project, we built a novel dataset – UIT-Drone21, to advance drone-based image analysis tasks with complex scenarios that promise new challenges. Our dataset was chosen from 23 short videos of approximately 13,066 fully labeled frames with bounding boxes for many tasks such as object detection, sing-object tracking, and multiple object tracking. We added approximately 2,304 frames (about 15,370 frames total) for object detection tasks.

UIT-Flower(2021)
UIT-Flower dataset includes 81,909 images for 21 flowers, which promises many challenges in building classification models in 4 perspectives:
- The flowers have a variety of colors. We do not limit fixed colors for one flower so that a flower can have different colors depending on the natural conditions in each other region.
- The flowers have the same color. Because we didn't limit the color of flowers, the different flowers also encounter the same color.
- The flowers have a variety of shapes. At each period of growth, flowers will have different shapes or are affected by weather conditions or care. The flowers also have mutant shapes, but the basic characteristics remain the same.
- Image contains noise factor. Flowers are often used for decoration or gifts, so images containing flowers often have other objects attached. For example, flowers are placed in vases or bunched together with other decorative items. However, we only keep the images when the images focus on the flower.

Vina-Food21(2021)
Vietnamese cuisine encompasses diverse dishes from the mainstream culinary traditions in all three regions of Vietnam to the street food with original and creative recipes. We conduct a small survey on the Internet to choose the most favorite street food and dishes in typical traditional southern Vietnamese meals.
VinaFood21 contains 13,950 images are corresponding to 21 dishes. This is a more comprehensive food dataset that surpasses existing Vietnamese Food datasets from the following three aspects.
- Larger data volume: VinaFood21 has 13,950 images from21dishes, which has created a new milestone for complexVietnamese food recognition.
- More extensive category coverage:It consists of21categories, which is about 2~3 times thatof existing Vietnamese food datasets.
- Higher diversity: Foodcategories from our dataset cover various high intra-class distances(different look but similar type) and low inter-class distances (similarlook but different type), including both street food and a daily meal.Moreover, our dataset is more challenging in various layouts, sidedishes, and dishes in different lighting conditions.
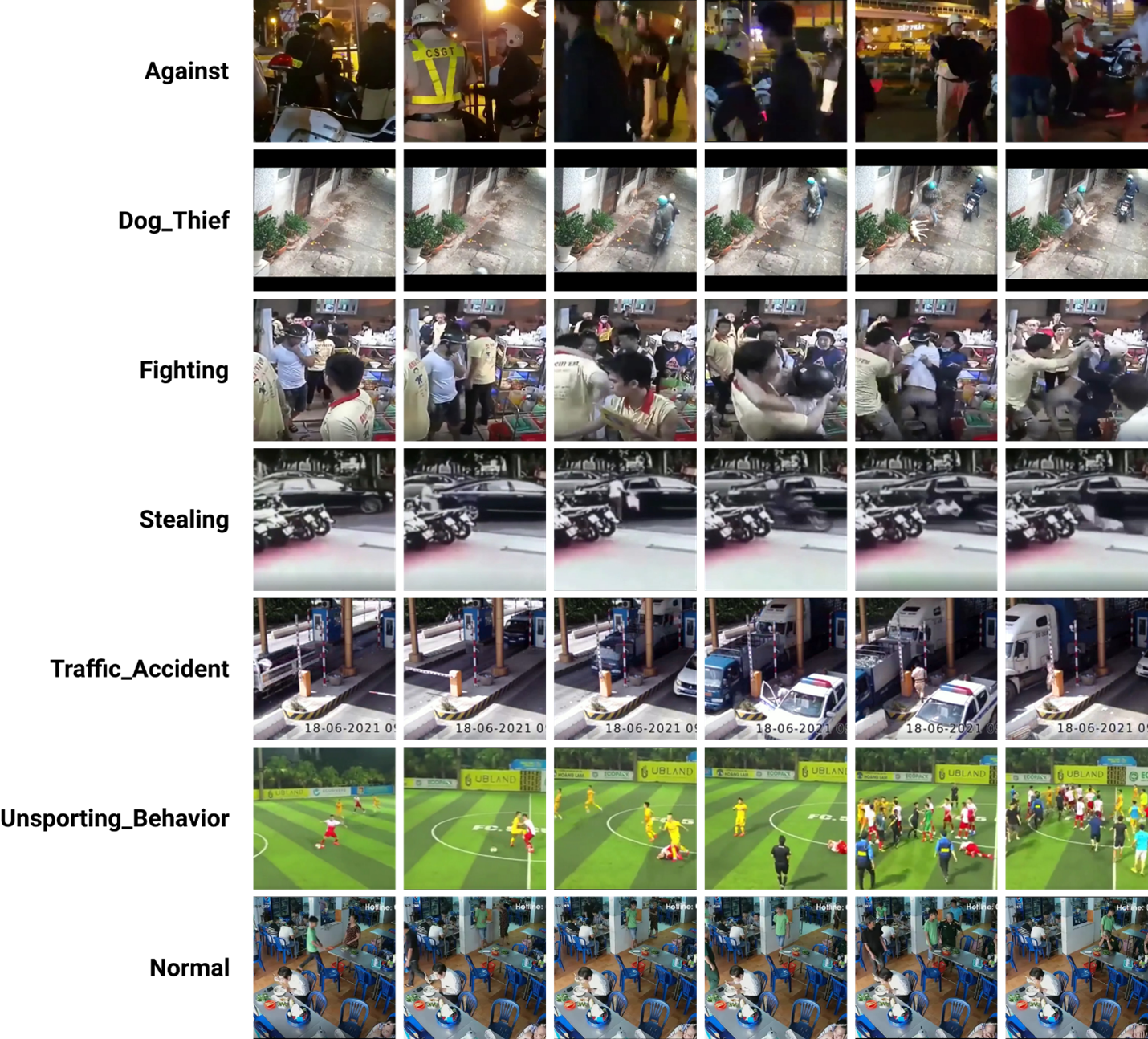
UIT-Anomaly(2022)
The UIT-Anomaly dataset includes a total of 224 muted videos captured at a frame rate of 30 fps with various resolutions. It has 104 normal and 120 anomalous videos. The total duration is more than 200 minutes, corresponding to 392,188 frames. We divide these videos into two subsets: the training set included 90 abnormal and 90 normal videos, while the test set consisted of the remaining 30 abnormal and the remaining 14 normal videos. Both training and test sets contain six classes of anomalies.
UIT-Anomaly has the following highlights:
- Data size: Compared to other datasets for the anomaly detection problem, UIT-Anomaly can be considered as a sizable dataset with a total duration of more than 200 minutes, containing 314,843 training frames and 77,345 testing frames.
- Vietnamese context: UIT-Anomaly is the first dataset containing many typical Vietnamese contexts. Most of the benchmark datasets currently available were shot in China (CHUK Avenue, UCSD Ped 1, UCSD Ped 2, ShanghaiTech) or from Western countries (Subway dataset, UMN) or other countries (UCF-Crime).
- Variety of backgrounds: UIT-Anomaly is not only diversified in terms of the number of unusual types, but also in terms of the range of contexts, with 18 scenes including the road, the private home, the parking area, and more in a variety of weather, lighting, and camera angles. This makes our dataset more realistic, but it also brings obstacles when tackling the problem of anomaly detection in complicated contexts.

VNAnomaly(2022)
The VNAnomaly dataset consists of 89 training videos and 96 evaluating videos that include real-world anomalies in Vietnamese street. The anomaly types contain 4 common human-related anomalies in the street of Vietnam including fighting, assault, vandalism, and robbery. Because the VNAnomaly is an unsupervised dataset, we will not explicitly define these anomaly types. The reason we choose the above anomaly types is the popularity of these types compared to other ones. In addition, these anomaly types are also relevant to the safety of public lives and assets in Vietnam’s urban environments. However, there are some unusual events that are not mentioned such as traffic accidents. Therefore, we will continue to provide more anomaly types soon. Our dataset surpasses existing unsupervised datasets from the following three aspects.
VNAnomaly has the following highlights:
- To the best of our knowledge, this is one of the first unsupervised datasets that capture the Vietnamese scene.
- Larger data volume: VNAnomaly has 578,609 training frames and 75,214 evaluating frames, which is bigger than existing unsupervised benchmark datasets.
- Higher scene diversity: Our dataset contains 36 scenes with different aspects such as different camera angles, times of the day. Furthermore, to ensure the context that the model learns in the training stage matches the testing phase, the scenes in the training set are required to be suitable with the testing set. As compared with ShanghaiTech dataset, number of scenes in our dataset triples them.

UIT-TASTET21(2022)
We present a dataset with 18 dishes typically found during the Vietnamese traditional Tet holiday. There are a total of 77,000 images divided into two definite sets with a ratio of 8:2. The training set consists of 63,840 images, whereas the test set has 14,041 images. The ratio of each food’s images in two subsets is randomly divided. Real-world data goes hand in hand with challenges; this means that the accuracy and performance of a deep learning model or machine learning model will be heavily influenced by the obstacle that the training data presents. By raising these concerns, we hope to lay the groundwork for optimal solutions proposed in the future:
- Food images contain multiple confounding factors. Dishes aren't always served separately but instead put close to each other to enrich the meal. In addition, eating utensils (bowls, plates, glasses, etc.) and decorative items (lamps, vases, tablecloths, etc.) also contribute to visual noise in the images.
- Dishes come in various forms. Although the same type of dishes, they are prepared using different recipes, resulting in a wide range of shapes and colors. Traditional dishes with a lot of designs will appeal to consumers, so this is an element that appears very often on data images.
- Several dishes with typical Vietnamese characteristics have relatively little data: Many delightful dishes are still unfamiliar with international friends, as are the facts on their data to which researchers have given little attention. Some foods have distinct flavors and a high commercial value (such as Banh in, Candied Ginger, Candied Kumquat, ...).
- Several dishes in this data collection have a lot of similarities: This sameness makes them very confusing and challenging. However, even if both products are made from the same materials and undergo similar processing, the final product is noticeably different, reflecting Vietnam's distinct regional identities.

UIT-VinaDeveS22(2022)
UIT-VinaDeveS22 has the following highlights:
- Collecting source: UIT-VinaDeveS22 is a fairly rare dataset in the present time that collect data from Vietnam department of transportation portal which presents the most truthfully and also be easy to apply for Vietnam traffic situations in the near future.
- Number of videos captured: UIT-VinaDeveS22 shows various scenes when the number of recorded source is up to 6 different videos which include many types of road such as crossroads, single carriageway or dual carriageway where the traffic density absolutely performs a big gap.
- Illuminate/Weather Conditions: Data includes different illuminate and weather condition i.e. daytime, night, clear and rain.

UIT-DODV-Ext Dataset(2022)
UIT-DODV-Ext is the largest dataset of Vietnamese document images with 5,000 images for three objects on the page: Table, Figure, Caption. Document images of the UIT-DODV-Ext dataset are Vietnamese publications such as scientific papers and textbooks in PDF, which were scanned and converted to be stored as images. UIT-DODV-Ext promises to pose many challenges from four main factors:
- Diversity of images: images in the UIT-DODV-Ext dataset are collected from various resources such as scanning by smartphones, physical scanners, and PDF files. Scanned images often have lower resolution than PDF files because natural factors in the scanning process make the document page blurry, distorted, skewed, or obscured.
- Diversity of documents: in comparison with previous image document datasets, UIT-DODV-Ext has both textbooks and scientific articles. Combining the diversity of images and the variety of documents creates challenges for deep learning models because our dataset has different domains.
- Diversity of layout: the document pages on UIT-DODV-Ext have significant variations in format. Specifically, the page from different scientific conferences/journals will have their templates (e.g., a document page can be represented in one column or two columns). Besides, textbooks are a big difference in the layout between traditional textbooks and innovative ones. Moreover, the current Vietnamese textbooks also have three different versions with formatting inconsistencies.
- The challenge comes from recognizing caption: most documents are presented as text, and captions are also part of the text. Because of the diversity of layouts, captions are not located in fixed positions (e.g., below or above figures and tables). Therefore, captions pose challenges for the detection and recognition model.